
Transformer Architecture Explained
For computer scientists, he’s the modern day version of Michael Jordan, albeit a bit nerdier.

When thinking about the immense impact of transformers on artificial intelligence, I always refer back to the story of Fei-Fei Li and Andrej Karpathy. Andrej Karpathy, co-founder of OpenAI and Phd student under Fei-Fei Li, is one of the most recognizable names in AI research. For computer scientists, he’s the modern day version of Michael Jordan, albeit a bit nerdier. As part of his Phd in 2015, Andrej pioneered a novel computer vision algorithm that described a photo in human natural language. Fei-Fei suggested, “Very Cool, now do it backwards”, to which Andrej immediately responded “ Ha Ha that’s impossible”.
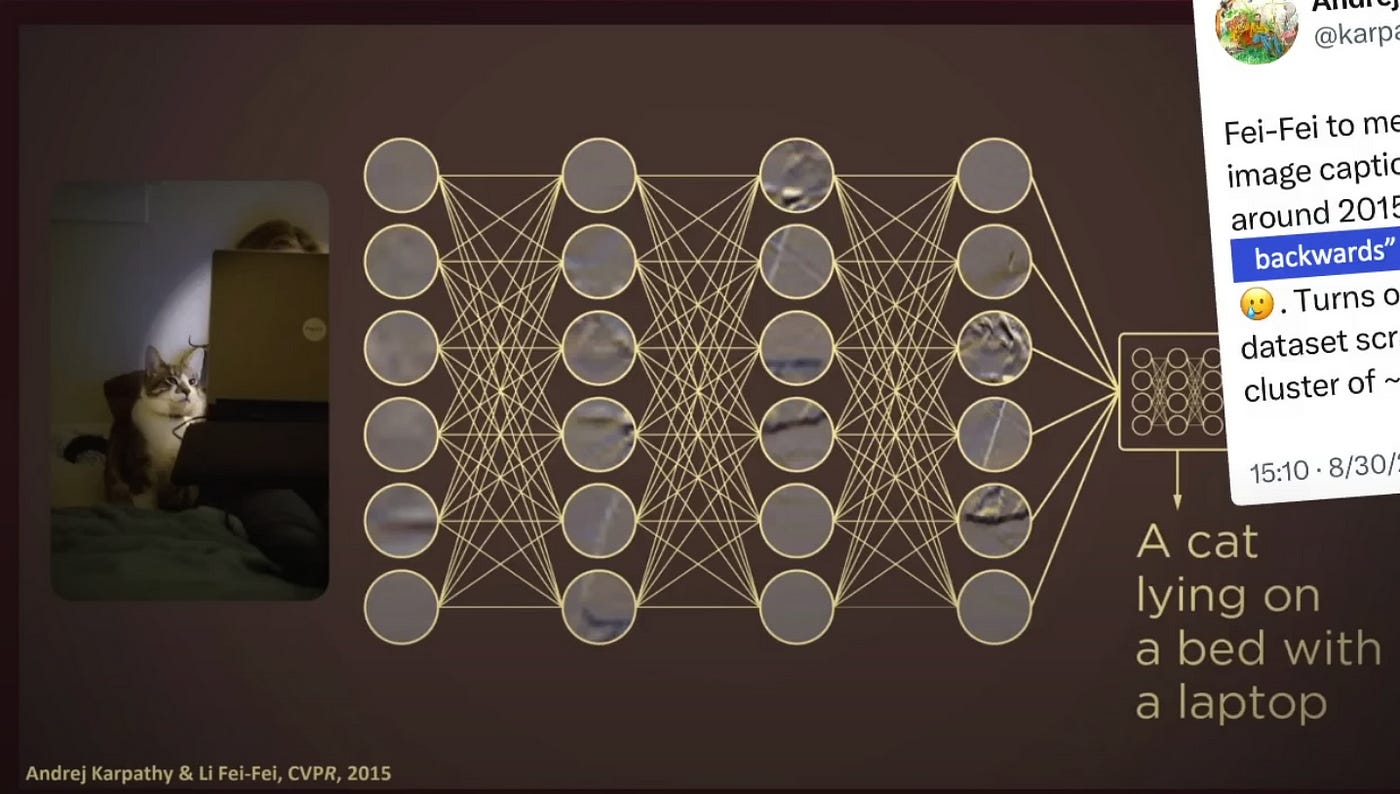
As we now know, it is in fact not impossible. Andrej was just missing a key piece of the puzzle that wouldn’t emerge onto the scene of Artificial intelligence until 2017. At NeurIPS 2017, the Google Brain team unveiled “Attention is All you Need”, a paper that would transform the landscape of machine translation, and urge in the era of LLMs. The paper highlighted the limitations of traditional sequence-to-sequence models, which rely on recurrence and convolution to process sequential data. Instead they proposed the “Transformer”, based solely on attention mechanisms, dispensing with recurrence and convolutions entirely. The idea was so revolutionary, that for years after, the best computer scientists in the world looked for alternative methods to no avail. So, what exactly is the Transformer, and what makes it so special?
What is a Transformer?
The Transformer is a model that introduced the novel idea of “self-attention”. At this point processing sequential data, for example input text, would be processed word by word through an RNN which would only consider the previous word. Self attention allows the model to process all parts of the sentence at the same time, accounting for the relationships between words. This allows computers to really “understand” the input in a human-like manner and generate enhanced output.
Transformer Architecture Broken Down:
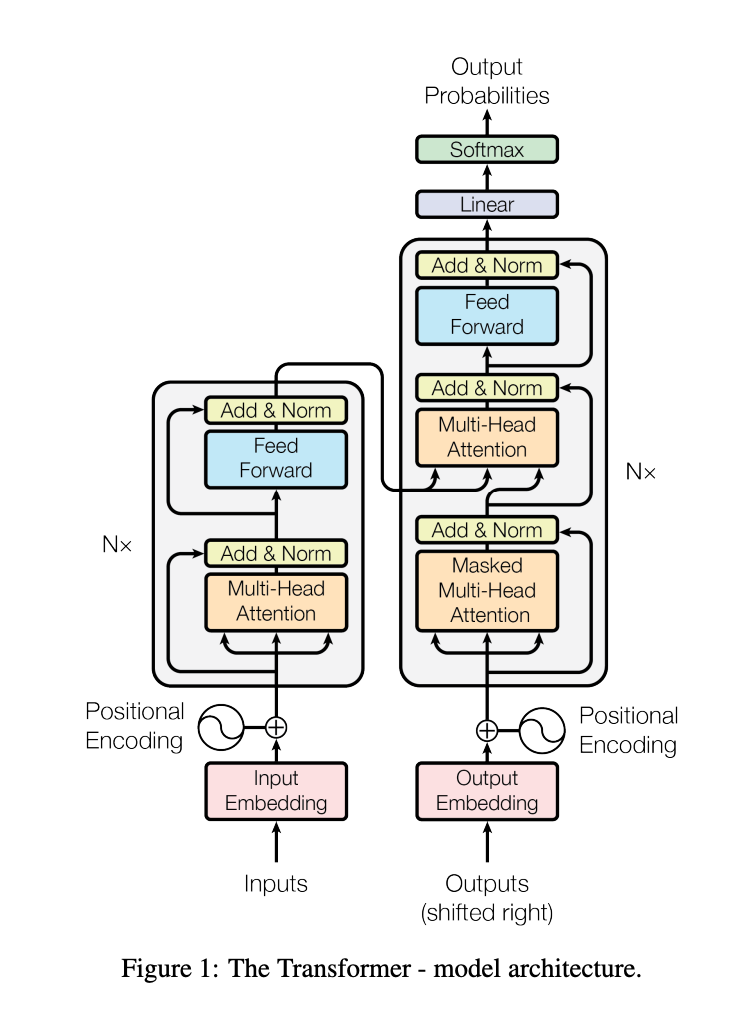
Encoder Block:
Tokenization: Transformers operate on numerical data, so the input text is broken down into smaller units called tokens. Tokens can be words, subwords, or even individual characters. In cases where a word is not present in the model’s vocabulary, transformers often break it down further into sub words or characters, which are then mapped to their respective IDs.

Input Embedding: Once the text is tokenized, each token is mapped to an embedding vector through a lookup table. If two pieces of text are similar, then the numbers in their corresponding vectors are similar to each other. Every word is mapped to a point in the embedding space where similar words in meaning are physically closer to each other. The word embeddings for all the words in the sentence are determined simultaneously.
Positional Encoding: Once the vector for each token is generated they are added together to represent the input text. However, we first need to account for the fact that the order of words in a sentence impacts its meaning. The sentence “I’m not sad, I’m happy” and the sentence “I’m not happy, I’m sad”, will result in the same added vector, despite the fact they have different meanings. As a result, Positional encoding vectors are then added to the word embeddings to incorporate the position information into the embeddings.

Multi-Head Attention:
Self-attention allows the model to weigh the importance of each word in a sentence relative to every other word. An attention vector is computed for each word, highlighting its relationship to the other words in the sentence. Consider the example of the two phrases: “The bank of the river” and “Money in the bank”. The word “bank” has different meanings in both phrases, and this must be understood to understand the meaning of the sentence. When an attention vector is computed for “bank” in the first sentence, greater weight will be given to bank’s relationship with river. And for the second sentence, it will be bank’s relationship with money. The two related words in the sentence are moved closer in the word embedding space. The new respective embedding vectors for bank will carry some of the information of the neighboring words.

Add & Norm: The residual connection(Add) is used to add the original input of a sub-layer directly to its output. This means the attention vector produced by the Multi-Head Attention mechanism is added to the original embedding vector (with positional encoding) that was input into this block. After the residual connection, the combined output is normalized using Layer Normalization(Norm). Layer Normalization helps stabilize and speed up the training process by normalizing the summed vectors across the features.

Feed-Forward Layer: The Feed-Forward layer is a fully connected neural network that refines and enhances word embeddings after the self-attention mechanism has contextualized them. It applies two linear transformations with a non-linear activation function(ReLU) to the data, allowing the model to capture more complex patterns and relationships. It also refines features extracted by the self attention layer, emphasizing important features and suppressing less relevant ones. Unlike self attention, FF Layer processes each token’s embedding independently, so all tokens in the sequence can be processed simultaneously. Residual connection and layer normalization is then again applied to the output.

Decoder Block:
The goal of the decoder block is to take in encoder output and generate a relevant response. If we asked ChatGpt, “How do I cook scrambled eggs?”, the decoder should be able to process the input and generate a relevant answer through its training data. It accomplishes this through next-word prediction, generating one token at a time.
Output Embedding + Positional Encoding: During the training phase for english-french translation, the output French sentence would be fed to the decoder. The French sentence would similarly need to be tokenized, embedded into a vector, and applied with positional encoding.
Masked Multi-Head Attention: During training, a mask is applied to the output sequence to ensure that each token in the output sequence is predicted based only on the tokens that have already been generated. It is crucial that the model does not “cheat” by looking ahead at future tokens. The mask ensures that the model only uses past and present information, maintaining the integrity of the sequence generation process. After applying the mask, the attention scores are computed as usual. The output of the masked multi-head attention block is a set of contextual embeddings for each token. These embeddings are “aware” of the tokens that precede them in the sequence but are not influenced by tokens that come later.

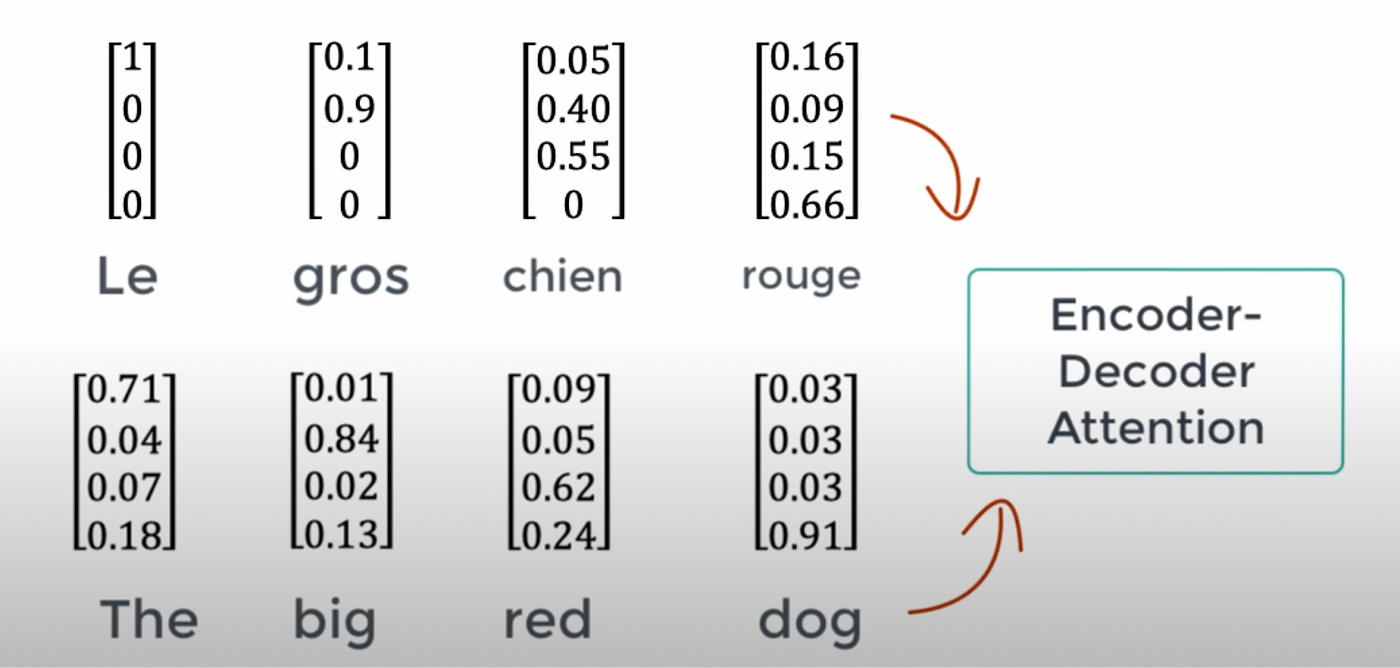
Encoder-Decoder Multi-Head Attention Block: The contextual embeddings from the masked attention block are intermediate representations and passed on to Encoder-Decoder for further processing. This block allows the decoder to focus on relevant parts of the input sequence(Encoder Output), while generating the output sequence. For example, when generating a vector for “Le” in English-French translation, the encoder-decoder will likely focus on “the” in the input sequence. The Query vectors come from the decoder’s current state(after masked attention), while the Key and Value vectors come from the encoder’s output. The dot product attention mechanism is used to calculate how much “attention” each word in the decoder should give to each word in the encoded input sequence. As usual, the attention scores are passed through softmax, and attention weights are then used to compute a weighted sum of the Value vectors from the encoder. This weighted sum is the final output of the attention mechanism for the current word in the decoder. Remember that multi-head attention is still used here. After passing through the encoder-decoder attention block, each token in the decoder has an output vector that captures the relationship between that token and the entire input sequence. These vectors are contextualized representations that integrate both the previously generated tokens in the decoder and relevant parts of the input sequence.
Feed-Forward Layer: These intermediate vector representations from the Encoder-Decoder block are passed through a feed-forward neural network. The feed-forward network processes these vectors further, adding additional non-linear transformations and enhancing the representation of each token. Residual connection and Layer normalization is again applied.
Linear Classifier Layer: The Linear Layer is a fully connected neural network layer that maps the high-dimensional output vector to a new vector with dimensions equal to the size of the model’s vocabulary. The linear layer takes the output vector from the decoder and generates a score vector, with a score for each possible token in the vocabulary. Only the contextualized vector for the final word/token in the decoder sequence is used to generate the score vector. In simpler terms, you can think of the linear layer as taking this rich embedding and comparing it to all the word vectors (or embeddings) in the vocabulary. During training, the transformer model learns how to associate certain contextual embeddings with likely next words based on massive amounts of data.
Softmax Function: The SoftMax function is applied to the scores and converts them into probabilities. The model selects the token with the highest probability as the next word in the sequence, and the process repeats until the entire output sequence is generated.

Autoregression: During inference, after a token is predicted using the Linear and SoftMax layers, that predicted token is fed back into the decoder model and the whole masked-attention + Encoder-Decoder process repeats to predict the next token. This process is autoregressive, meaning that each new token is generated based on the tokens that have already been produced. For example, in the sentence, “The cat sits”, when predicting the next word after “sits” the model primarily utilizes the contextualized embedding for “sits” which already contains information about “The” and “cat”.
Scaled Dot-Product Attention(Basic Self-Attention): QKV
Each word in the input sequence is transformed into three vectors: Query(Q), Key(K), and Value(V). The vectors are created by multiplying the word embedding by three different learned weight matrices (one for each: Query, Key, and Value). Query vector represents what this word is looking for in other words to determine relevance. The Key vector represents what information the word contains or has to offer. The Value vector represents the actual word embedding or information.
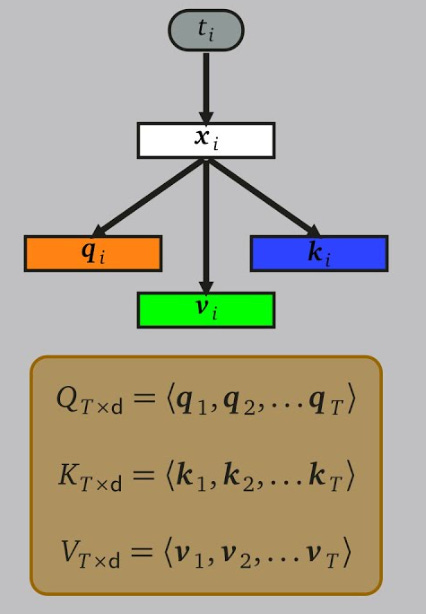
The attention score between a pair of words is computed by taking the dot product of the Query vector with the Key vector of another word. The attention mechanism computes attention scores between the Query vector of a specific word (the “focus” word) and the Key vectors of all words in the sentence. The attention scores are then normalized using a softmax function, summing to 1, and generating a probability distribution indicating how much “attention” the model should place on each word in the context of the focus word.

Each word’s Value vector is then weighted(multiplied) by its corresponding attention weight.

The model then sums up all the value vectors, creating a new vector representation for the focus word. This vector is a contextually rich embedding of the focus word, including information from all the other words in the sentence. Words with higher attention scores play a larger role in the focus word’s final embedding vector.

Note: The division by scaling factor sqrt(dK) is used to avoid the scenarios where large attention values(QKT) would result in small gradients. The softmax function is sensitive to the magnitude of its input values.

Multi-Head Attention(Deeper Dive):
The Transformer performs multiple attention functions in parallel. Each “head” in multi-head attention represents a separate attention mechanism. Each head focuses on a different aspect of the input seqeunce. One head might focus on syntactic relationships (e.g., subject-verb), while another might focus on semantic relationships(e.g., synonymy), and another could focus on temporal relationships. Each attention head has its own set of learned weight matrices for Queries, Keys, and Values. These matrices are what allow each head to focus on different aspects of the input data. The model adjusts these matrices through backpropagation during the training process, just like it does with other parameters, in order to minimize the loss function. After the attention heads have computed their outputs, the resulting vectors for the focus word are concatenated and linearly transformed, allowing the model to combine the different perspectives from each attention head into a single, cohesive vector embedding.

Vector Arithmetic in Word Embeddings:
Word embeddings are essentially high-dimensional vectors that represent words. The idea is that words with similar meanings have similar vectors, and the relationships between words can be captured by the spatial arrangement of their vectors. Vectors are typically learned from a large corpus of text using models like Word2Vec or GloVe.
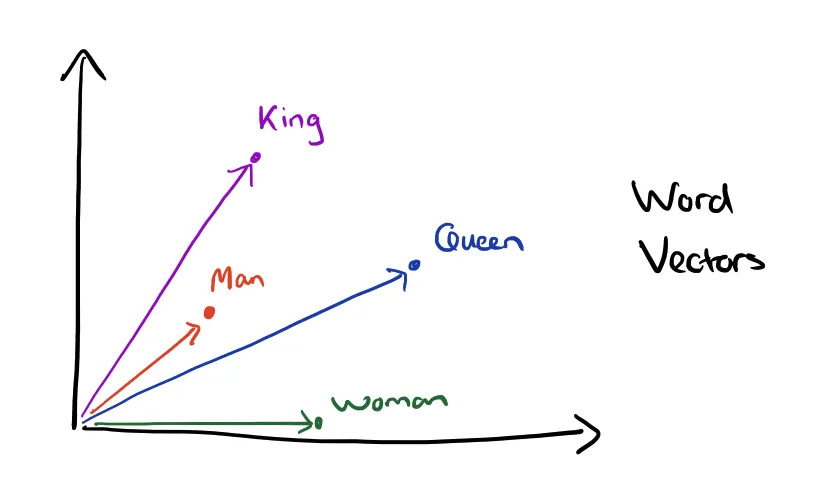
For example, you can subtract the vector for “Man” from the vector for “King” and add the vector for “Woman” to get the vector for “Queen”. Word vector arithmetic enables models to capture nuanced relationships between words without being explicitly programmed, reflecting how we might think about these relationships in the real world.

Transformers have transformed, for lack of a better word, a wide variety of research fields, primarily: NLP, Computer Vision, Multi-Modality, Audio and Speech Processing, and Signal Processing. I’m looking forward to seeing how further innovation around transformers plays a role in the advent of Intelligent Systems .
Sources: These are great resources, definitely check them out!